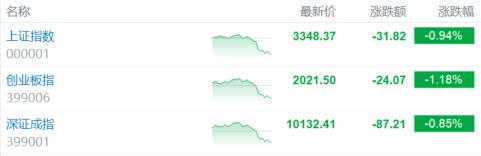
DeepSeek,由幻方量化旗下公司推出,凭借其低成本和强大的推理能力迅速走红,登顶多个应用商店下载榜首,并引发资本市场热潮。
DeepSeek的成功主要源于其V3模型在训练成本和计算效率上的显著提升,以及R1模型的创新性。R1模型摒弃了传统的基于人类反馈的强化学习(RLHF),采用纯粹的强化学习(RL)模式,通过设定“结果正确函数”和“思考过程函数”两个奖励函数,实现自我学习和优化,提升推理能力,同时降低了对标注数据的依赖。这种方法不仅显著降低了训练成本(约为OpenAI同类模型的1/30),还在数学、代码和自然语言推理任务上表现出色,性能比肩OpenAI o1。此外,R1模型的开源也缩小了开源和闭源模型的技术差距,对人工智能领域具有重要意义。
摩根士丹利基金认为,DeepSeek的火爆预示着AI领域未来发展将更加多元化,大模型成本的降低将加速AI应用的商业化进程。DeepSeek有望推动人工智能应用落地,带动训练端和推理端算力需求的爆发式增长,利好推理算力芯片和端侧算力。尽管美股科技股此前经历调整,但DeepSeek缩短了与闭源模型的差距,降低了市场对训练端算力投入的担忧,因此美股科技股仍具备投资机会。
至于DeepSeek概念行情的持续性,则取决于国内人工智能应用(如To B端的软件应用或SaaS公司)的商业化进程,以及端侧AI+硬件能否形成商业闭环。A股的推理侧、端侧算力芯片公司和软件应用头部公司,以及港股中积极布局人工智能的相关龙头企业,有望从DeepSeek带来的国内人工智能浪潮中受益。